#proxy pattern microservice
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 4 main sources of revenue.
Text
Pods in Kubernetes Explained: The Smallest Deployable Unit Demystified
As the foundation of Kubernetes architecture, Pods play a critical role in running containerized applications efficiently and reliably. If you're working with Kubernetes for container orchestration, understanding what a Pod is—and how it functions—is essential for mastering deployment, scaling, and management of modern microservices.
In this article, we’ll break down what a Kubernetes Pod is, how it works, why it's a fundamental concept, and how to use it effectively in real-world scenarios.
What Is a Pod in Kubernetes?
A Pod is the smallest deployable unit in Kubernetes. It encapsulates one or more containers, along with shared resources such as storage volumes, IP addresses, and configuration information.
Unlike traditional virtual machines or even standalone containers, Pods are designed to run tightly coupled container processes that must share resources and coordinate their execution closely.
Key Characteristics of Kubernetes Pods:
Each Pod has a unique IP address within the cluster.
Containers in a Pod share the same network namespace and storage volumes.
Pods are ephemeral—they can be created, destroyed, and rescheduled dynamically by Kubernetes.
Why Use Pods Instead of Individual Containers?
You might ask: why not just deploy containers directly?
Here’s why Kubernetes Pods are a better abstraction:
Grouping Logic: When multiple containers need to work together—such as a main app and a logging sidecar—they should be deployed together within a Pod.
Shared Lifecycle: Containers in a Pod start, stop, and restart together.
Simplified Networking: All containers in a Pod communicate via localhost, avoiding inter-container networking overhead.
This makes Pods ideal for implementing design patterns like sidecar containers, ambassador containers, and adapter containers.
Pod Architecture: What’s Inside a Pod?
A Pod includes:
One or More Containers: Typically Docker or containerd-based.
Storage Volumes: Shared data that persists across container restarts.
Network: Shared IP and port space, allowing containers to talk over localhost.
Metadata: Labels, annotations, and resource definitions.
Here’s an example YAML for a single-container Pod:
yaml
CopyEdit
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
spec:
containers:
- name: myapp-container
image: myapp:latest
ports:
- containerPort: 80
Pod Lifecycle Explained
Understanding the Pod lifecycle is essential for effective Kubernetes deployment and troubleshooting.
Pod phases include:
Pending: The Pod is accepted but not yet running.
Running: All containers are running as expected.
Succeeded: All containers have terminated successfully.
Failed: At least one container has terminated with an error.
Unknown: The Pod state can't be determined due to communication issues.
Kubernetes also uses Probes (readiness and liveness) to monitor and manage Pod health, allowing for automated restarts and intelligent traffic routing.
Single vs Multi-Container Pods
While most Pods run a single container, Kubernetes supports multi-container Pods, which are useful when containers need to:
Share local storage.
Communicate via localhost.
Operate in a tightly coupled manner (e.g., a log shipper running alongside an app).
Example use cases:
Sidecar pattern for logging or proxying.
Init containers for pre-start logic.
Adapter containers for API translation.
Multi-container Pods should be used sparingly and only when there’s a strong operational or architectural reason.
How Pods Fit into the Kubernetes Ecosystem
Pods are not deployed directly in most production environments. Instead, they're managed by higher-level Kubernetes objects like:
Deployments: For scalable, self-healing stateless apps.
StatefulSets: For stateful workloads like databases.
DaemonSets: For deploying a Pod to every node (e.g., logging agents).
Jobs and CronJobs: For batch or scheduled tasks.
These controllers manage Pod scheduling, replication, and failure recovery, simplifying operations and enabling Kubernetes auto-scaling and rolling updates.
Best Practices for Using Pods in Kubernetes
Use Labels Wisely: For organizing and selecting Pods via Services or Controllers.
Avoid Direct Pod Management: Always use Deployments or other controllers for production workloads.
Keep Pods Stateless: Use persistent storage or cloud-native databases when state is required.
Monitor Pod Health: Set up liveness and readiness probes.
Limit Resource Usage: Define resource requests and limits to avoid node overcommitment.
Final Thoughts
Kubernetes Pods are more than just containers—they are the fundamental building blocks of Kubernetes cluster deployments. Whether you're running a small microservice or scaling to thousands of containers, understanding how Pods work is essential for architecting reliable, scalable, and efficient applications in a Kubernetes-native environment.
By mastering Pods, you’re well on your way to leveraging the full power of Kubernetes container orchestration.
0 notes
Text
Istio Service Mesh Essentials: Simplifying Microservices Management
In today's cloud-native world, microservices architecture has become a standard for building scalable and resilient applications. However, managing the interactions between these microservices introduces challenges such as traffic control, security, and observability. This is where Istio Service Mesh shines.
Istio is a powerful, open-source service mesh platform that addresses these challenges, providing seamless traffic management, enhanced security, and robust observability for microservices. This blog post will dive into the essentials of Istio Service Mesh and explore how it simplifies microservices management, complete with hands-on insights.
What is a Service Mesh?
A service mesh is a dedicated infrastructure layer that facilitates secure, fast, and reliable communication between microservices. It decouples service-to-service communication concerns like routing, load balancing, and security from the application code, enabling developers to focus on business logic.
Istio is one of the most popular service meshes, offering a rich set of features to empower developers and operations teams.
Key Features of Istio Service Mesh
1. Traffic Management
Istio enables dynamic traffic routing and load balancing between services, ensuring optimal performance and reliability. Key traffic management features include:
Intelligent Routing: Use fine-grained traffic control policies for canary deployments, blue-green deployments, and A/B testing.
Load Balancing: Automatically distribute requests across multiple service instances.
Retries and Timeouts: Improve resilience by defining retry policies and request timeouts.
2. Enhanced Security
Security is a cornerstone of Istio, providing built-in features like:
Mutual TLS (mTLS): Encrypt service-to-service communication.
Authentication and Authorization: Define access policies using identity-based and attribute-based rules.
Secure Gateways: Secure ingress and egress traffic with gateways.
3. Observability
Monitoring microservices can be daunting, but Istio offers powerful observability tools:
Telemetry and Metrics: Gain insights into service performance with Prometheus and Grafana integrations.
Distributed Tracing: Trace requests across multiple services using tools like Jaeger or Zipkin.
Service Visualization: Use tools like Kiali to visualize service interactions.
Hands-On with Istio: Setting Up Your Service Mesh
Here’s a quick overview of setting up and using Istio in a Kubernetes environment:
Step 1: Install Istio
Download the Istio CLI (istioctl) and install Istio in your Kubernetes cluster.
Deploy the Istio control plane components, including Pilot, Mixer, and Envoy proxies.
Step 2: Enable Your Services for Istio
Inject Istio's Envoy sidecar proxy into your service pods.
Configure Istio Gateway and VirtualService resources for external traffic management.
Step 3: Define Traffic Rules
Create routing rules for advanced traffic management scenarios.
Test mTLS to secure inter-service communication.
Step 4: Monitor with Observability Tools
Use built-in telemetry to monitor service health.
Visualize the mesh topology with Kiali for better debugging and analysis.
Why Istio Matters for Your Microservices
Istio abstracts complex network-level tasks, enabling your teams to:
Save Time: Automate communication patterns without touching the application code.
Enhance Security: Protect your services with minimal effort.
Improve Performance: Leverage intelligent routing and load balancing.
Gain Insights: Monitor and debug your microservices with ease.
Conclusion
Mastering Istio Service Mesh Essentials opens up new possibilities for managing microservices effectively. By implementing Istio, organizations can ensure their applications are secure, resilient, and performant.
Ready to dive deeper? Explore Istio hands-on labs to experience its features in action. Simplify your microservices management journey with Istio Service Mesh!
Explore More with HawkStack
Interested in modern microservices solutions? HawkStack Technologies offers expert DevOps tools and support, including Istio and other cloud-native services. Reach out today to transform your microservices infrastructure! For more details - www.hawkstack.com
#redhatcourses#information technology#containerorchestration#kubernetes#docker#containersecurity#container#linux#aws#hawkstack#hawkstack technologies
0 notes
Text
6 Key Design Patterns You Will Learn in Elastic Kubernetes Services Training
Elastic Kubernetes Services (EKS) is a powerful tool for managing containerized applications at scale, and mastering it requires a solid understanding of various design patterns.
These patterns help solve common problems and ensure that applications are robust, scalable, and maintainable.
In Elastic Kubernetes Services training, you will encounter several key design patterns that are essential for using EKS efficiently and effectively.
Here are six key design patterns you will learn.
1. Microservices Pattern
The microservices pattern is fundamental to modern application architecture and a core EKS training concept.
This pattern involves breaking down an application into smaller, loosely coupled services that can be developed, deployed, and scaled independently.
EKS provides an ideal platform for running microservices due to its ability to manage containerized applications efficiently. You will learn how to design, deploy, and manage microservices on EKS, ensuring your applications are modular and scalable.
2. Sidecar Pattern
The sidecar pattern involves deploying a helper container (sidecar) alongside the main application container within the same pod.
This pattern is commonly used for logging, monitoring, and networking functions that support the primary application.
In EKS training, you will learn how to implement the sidecar pattern to enhance your application's capabilities without modifying the primary container. This approach simplifies maintenance and upgrades of auxiliary services.
3. Ambassador Pattern
The ambassador pattern offloads common tasks such as API gateway functions, authentication, and rate limiting from the main application container to a proxy container (ambassador).
This pattern helps in separating concerns and allows the main application to focus on its core functionality.
During EKS training, you will explore how to configure and deploy ambassador containers to handle external communication, improve security, and manage traffic efficiently.
4. Adapter Pattern
The adapter pattern (or adapter proxy) is used to make two incompatible interfaces compatible.
In the context of Kubernetes, this often involves adapting legacy systems or third-party services to work seamlessly with your containerized applications.
EKS training will cover how to use the adapter pattern to integrate different systems and services, ensuring that your applications can communicate and function correctly within the Kubernetes environment.
5. Circuit Breaker Pattern
The circuit breaker pattern is crucial for building resilient applications that can handle failures gracefully.
This pattern involves monitoring the health of services and temporarily halting requests to a failing service to prevent cascading failures.
EKS training will teach you how to implement the circuit breaker pattern using tools like Istio and Envoy, which provide advanced traffic management and resilience features. This ensures that your applications remain robust and can recover from failures quickly.
6. Blue-Green Deployment Pattern
The blue-green deployment pattern minimizes downtime and reduces risk during deployments.
It involves running two identical production environments (blue and green), with only one receiving live traffic simultaneously.
You can deploy updates to the inactive environment and switch traffic to it once testing is complete. In EKS training, you will learn how to set up and manage blue-green deployments, allowing seamless updates and rollbacks.
Conclusion
Elastic Kubernetes Services training equips you with the knowledge and skills to implement essential design patterns that enhance the scalability, resilience, and maintainability of your applications.
By mastering these six key design patterns—microservices, sidecar, ambassador, adapter, circuit breaker, and blue-green deployment—you will be well-prepared to build robust and efficient applications on EKS.
These patterns not only address common challenges but also enable you to leverage the full potential of Kubernetes in your organization.
0 notes
Text
NVIDIA Omniverse Cloud Sensor RTX Raised Physical AI

NVIDIA Omniverse Cloud Sensor RTX NVIDIA unveiled NVIDIA Omniverse Cloud Sensor RTX, a collection of microservices that expedite the construction of completely autonomous machines of all kinds by enabling physically realistic sensor simulation.
An industry worth billions of dollars is developing around sensors, which supply the information required by humanoids, industrial manipulators, mobile robots, autonomous cars, and smart environments to understand their environment and make judgements. Before deploying in the real world, developers can test sensor perception and related AI software at scale in physically accurate, realistic virtual environments with NVIDIA Omniverse Cloud Sensor RTX, which improves safety while saving money and time.
“Training and testing in physically based virtual worlds is necessary for developing safe and dependable autonomous machines powered by generative physical AI,” stated Rev Lebaredian, NVIDIA’s vice president of simulation and Omniverse technologies. “NVIDIA Omniverse Cloud Sensor RTX microservices will help accelerate the next wave of AI by enabling developers to easily build large-scale digital twins of factories, cities, and even Earth.”
Boosting Simulation at Large Scale Omniverse Cloud Sensor RTX, which is based on the OpenUSD framework and uses NVIDIA RTX’s ray-tracing and neural-rendering technologies, combines synthetic data with real-world data from cameras, radar, lidar, and videos to expedite the development of virtual environments.
The microservices can be used to simulate a wide range of tasks, even for scenarios with limited real-world data. Examples of these tasks include determining whether a robotic arm is functioning properly, whether an airport luggage carousel is operational, whether a tree branch is obstructing a roadway, whether a factory conveyor belt is moving, and whether a robot or human is nearby.
Research Successes Fuel Real-World Implementation The unveiling of the Omniverse Cloud Sensor RTX coincides with NVIDIA’s first-place victory in the Autonomous Grand Challenge for End-to-End Driving at Scale, held in conjunction with the Computer Vision and Pattern Recognition conference.
With Omniverse Cloud Sensor RTX, makers of autonomous vehicle (AV) simulation software may duplicate the winning methodology of NVIDIA researchers in high-fidelity simulated environments. This enables AV developers to test self-driving scenarios in realistic situations before deploying AVs in real life.
Access and Availability of Ecosystems Among the first software developers to receive access to NVIDIA’s Omniverse Cloud Sensor RTX for AV creation are Foretellix and MathWorks.
Additionally, Omniverse Cloud Sensor RTX will shorten the time required for physical AI prototype by allowing sensor makers to test and integrate digital twins of their sensors in virtual environments.
NVIDIA was today recognised as the Autonomous Grand Challenge winner at the Computer Vision and Pattern Recognition (CVPR) conference, taking place this week in Seattle, in an effort to hasten the development of self-driving cars.
NVIDIA Research outperformed more than 400 entrants globally this year in the End-to-End Driving at Scale category, building on its victory in 3D Occupancy Prediction from the previous year.
This significant achievement demonstrates the value of generative AI in developing applications for real-world AI deployments in the field of autonomous vehicle (AV) development. In addition, the technology can be used in robotics, healthcare, and industrial settings.
The CVPR Innovation Award was given to the winning proposal as well, honouring NVIDIA’s methodology for enhancing “any end-to-end driving model using learned open-loop proxy metrics.”
Advancing Generative Physical AI in the Future Around the globe, businesses and researchers are working on robotics and infrastructure automation driven by physical AI, or models that can comprehend commands and carry out difficult tasks on their own in the actual world.
Reinforcement learning is used in simulated environments by generative physical AI. It sees the world through realistically rendered sensors, acts in accordance with the rules of physics, and analyses feedback to determine what to do next. Advantages
Simple to Adjust and Expand With Omniverse SDKs’ easily-modifiable extensions and low- and no-code sample apps, you may create new tools and workflows from the ground up.
Improve Your Applications for 3D Omniverse Cloud APIs boost software solutions with OpenUSD, RTX, faster computing, and generative AI.
Implement Anywhere Create and implement unique software on virtual or RTX-capable workstations, or host and broadcast your programme via Omniverse Cloud.
Features Link and Accelerate 3D Processes
Utilise generative AI, RTX, and the OpenUSD technologies to create 3D tools and applications that enhance digital twin use cases with improved graphics and interoperability.
SDK, or software development kit Construct and Implement New Apps With Omniverse Kit SDK, you can begin creating bespoke tools and apps for both local and virtual workstations from start. Use the Omniverse Cloud platform-as-a-service to publish and stream content, or use your own channels.
APIs for Clouds Boost Your Portfolio of Software Simply call Omniverse Cloud APIs to integrate OpenUSD data interoperability and NVIDIA RTX physically based, real-time rendering into your apps, workflows, and services.
Integrate Generative AI with 3D Processes Applications developed on Omniverse SDKs or powered by Omniverse Cloud APIs can easily link to generative AI agents for language- or visual-based content generation, such as models built on the NVIDIA Picasso foundry service, thanks to OpenUSD’s universal data transfer characteristics.
Read more on Govindhtech.com
#OmniverseCloudSensorRTX#OmniverseCloud#Omniverse#nvidia#ai#nvidiartx#rtx#technology#technews#news#govindhtech
0 notes
Text
API Management Boomi

API Management with Boomi: Streamline Your API Ecosystem
APIs (Application Programming Interfaces) are the backbone of modern digital enterprises. They provide the connective tissue between various applications, systems, and data sources, facilitating seamless communication. However, with a growing number of APIs, managing them effectively becomes a critical challenge. This is where Boomi’s API Management solution comes into play.
What is API Management?
API Management encompasses the entire lifecycle of APIs, including:
Design and Development: Crafting well-structured and robust APIs to ensure interoperability.
Deployment and Publishing: Making APIs accessible to internal and external consumers.
Security: Implementing robust authentication and authorization mechanisms to protect sensitive data and resources accessed through APIs.
Monitoring and Analytics: Tracking API usage patterns, performance metrics, and potential issues.
Versioning: Managing different iterations of an API to maintain backward compatibility and allow organized evolution.
Developer Portal: Providing a centralized space for developers to discover, access, and subscribe to APIs.
Why Boomi API Management?
Boomi’s API Management solution offers a comprehensive set of tools and features designed to simplify and streamline the management of APIs within your organization:
Intuitive Interface: Boomi shines with its user-friendly, drag-and-drop interface, which makes API creation and management accessible even to non-technical users.
Seamless Integration with the Boomi Platform: Leverage the Boomi platform’s extensive integration capabilities to connect your APIs with various internal and external systems, facilitating data flow and process orchestration.
Flexible Deployment: Boomi’s API Gateway can be deployed on-premises, in the cloud, or in hybrid environments to match your enterprise architecture.
Robust Security: To safeguard your APIs, implement fine-grained security controls, including API keys, OAuth, OpenID Connect, and SAML.
Developer Portal: Offer a self-service portal for developers to discover, explore, test, and subscribe to your APIs, fostering seamless collaboration.
Critical Use Cases for Boomi API Management
Internal Integration: Facilitate integration and communication between different internal applications and systems, streamlining business processes.
Partner Ecosystems: Enable secure and controlled data sharing with business partners, opening up new revenue generation and collaboration opportunities.
Microservices Architectures: These architectures support the development and management of microservices, allowing for granular scalability and flexibility throughout your IT landscape.
Mobile and IoT Enablement: Expose APIs to power mobile apps and connect with IoT devices, extending your digital reach.
Getting Started with Boomi API Management
Boomi’s API Management provides a straightforward approach to get up and running quickly:
Design your API: Use Boomi’s visual tools to define your API’s endpoints, resources, and methods.
Deploy API Components: You can deploy your API as either an API Service or an API Proxy to a Boomi API Gateway.
Configure Security: Implement authentication and authorization mechanisms best suited for your API’s use case.
Publish to the Developer Portal: Showcase your API in the developer portal, providing documentation and subscription plans.
The Bottom Line
Boomi API Management helps you effectively govern and control the entire lifecycle of your APIs. This leads to improved efficiency, enhanced security, and seamless integration within your digital ecosystem. If you’re looking to streamline your API strategy, Boomi API Management is a powerful solution to explore.
youtube
You can find more information about Dell Boomi in this Dell Boomi Link
Conclusion:
Unogeeks is the No.1 IT Training Institute for Dell Boomi Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Dell Boomi here – Dell Boomi Blogs
You can check out our Best In Class Dell Boomi Details here – Dell Boomi Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeek
0 notes
Video
youtube
Proxy Design Pattern Explained with Examples for Software Developers & B...
Full Video Link https://youtu.be/6q25hg5fWX0
Hello friends, new #video on #proxydesignpattern #tutorial with #examples is published on #codeonedigest #youtube channel. Learn #microservice #proxy #designpattern #programming #coding with codeonedigest.
@java #java #aws #awscloud @awscloud @AWSCloudIndia #salesforce #Cloud #CloudComputing @YouTube #youtube #azure #msazure #proxypattern #proxypatternmicroservices #proxypatternjava #proxypatterninsoftwareengineering #proxypatterntutorial #proxypatternexplained #proxypatternexample #proxydesignpattern #proxydesignpatternjava #proxydesignpatternspringboot #proxydesignpatternexample #proxydesignpatterntutorial #proxydesignpatternexplained #microservicedesignpatterns #microservicedesignpatterns #microservicedesignpatternsspringboot #microservicedesignpatternssaga #microservicedesignpatternsinterviewquestions #microservicedesignpatternsinjava #microservicedesignpatternscircuitbreaker #microservicedesignpatternsorchestration #decompositionpatternsmicroservices #decompositionpatterns #monolithicdecompositionpatterns #integrationpatterns #integrationpatternsinmicroservices #integrationpatternsinjava #integrationpatternsbestpractices #databasepatterns #databasepatternsmicroservices #microservicesobservabilitypatterns #observabilitypatterns #crosscuttingconcernsinmicroservices #crosscuttingconcernspatterns #servicediscoverypattern #healthcheckpattern #sagapattern #circuitbreakerpattern #cqrspattern #commandquerypattern #proxypattern #Proxypattern #branchpattern #eventsourcingpattern #logaggregatorpattern
#youtube#proxy pattern#proxy design pattern#proxy pattern microservice#microservice design pattern#microservice pattern#microservices#java#design patterns#software design patterns#java design patterns
1 note
·
View note
Text
Refactor Legacy Systems Without Risks
The strangler fig pattern is about incrementally migrating from a legacy system to a modern one. We gradually replace the functional blocks of a system with new blocks, strangle the older system’s functionalities one by one, and eventually replace everything with a new system. Once the older system is entirely strangled, it can be decommissioned by legacy systems.
When to use a strangler fig pattern
You can use this pattern when gradually migrating from a back-end application to a new architecture. The strangler fig pattern may not be suitable if the requests to the back-end system cannot be intercepted. When dealing with smaller systems without much complexity, it’s better to go for a wholesale replacement rather than choosing this pattern. Here’s how you can implement the strangler fig pattern:
Transform
Given below is an example of legacy code and architecture, where all the modules are tightly coupled, and it is hard to maintain them in the same condition with upcoming modern technology. Here, the loan service contains three services: personal, partner, and business loans.
Code Snippet:
We choose the personal loan method as the first to refactor. It could be unreliable, inefficient, outdated, or even hard to get skilled developers to maintain the same legacy code.
Let’s make a new implementation for the personal loan service and divide it into separate classes or even a microservice. After correcting or refactoring our code snippet, we can create a Proxy class for handling both new and old approaches.
We have developed a new API with a separate database. Initially, all services used a shared database, but as part of code refactoring, the personal loan module had to be decoupled from the existing database. The same applies to the API endpoint.
Coexist: where two implementations coexist together.
Here we have extracted another layer abstraction from the loan service and made it coexist with the original service. Both services provide the same functionality, and the signature of the services is also the same. The proxy will decide whether the call goes to a new API or an existing service.
Run new service with a fallback of old service: In such a scenario, we always have a safety buffer if the new one fails.
Run both services and compare the output to confirm whether the new one works fine. In such a scenario, to avoid duplicate loans or transactions, we should turn off all external references and assume that we accept loan data only from one source.
Use a feature flag to decide whether to use the new API or the old one. Here in the configuration, we can set a flag, and it will choose how the call will work — whether with legacy API or with Newly developed service.
Tests
While refactoring, we might miss some tests, or the existing tests might be heavy to maintain. The proxy service created helps us ensure that the implementation completely covers the old one.
Let’s implement integration or even e2e tests, where we test observable behaviors instead of implementation details. Remember that anything we refactor or change should have a certain level of test coverage. The better the coverage, the more confidence we get in how the code works. If the refactoring code does not contain enough tests, we should start by covering it and writing test cases for all features, behaviors, and edge cases.
We should start testing the Proxy class if unit tests cannot cover the code. Sometimes e2e tests might be the only way to cover both implementations.
Eliminate
Once we catch up and mitigate all the problems in the new approach, we can eliminate the legacy code. Hereafter, the personal loan module directly approaches the new API.
Summary
We can split code refactoring into multiple iterations and releases. If we are uncertain whether the new approach will work exactly as expected, we can prepare a fallback mechanism. So, if the new approach doesn’t work, we can quickly switch to the legacy systems. This method gives us a security buffer to use for safe refactoring.
1 note
·
View note
Text
Cloud Service Mesh Market

Global Cloud Service Mesh Market Outlook
““According to this latest study, the growth in the Cloud Service Mesh market will change significantly from the previous year. Over the next six years, Cloud Service Mesh will register a CAGR in terms of revenue, and the global market size will reach USD in millions by 2028.”
Cloud Service Mesh Market applies the most effective of each primary and secondary analysis to weigh upon the competitive landscape and also the outstanding market players expected to dominate Cloud Service Mesh Market place for the forecast 2022-2028.
Cloud Service Mesh Market Insights:
The service mesh is often implemented by providing a proxy instance, referred to as a sidecar. Interservice monitoring, communications, and security issues are all handled by sidecars, as is anything else that can be abstracted away from the individual services. Authorisation, encryption Service discovery, traceability, observability, load balancing, authentication, and support for the circuit breaker pattern are all included in the mesh. Developers can handle the application code in the services development, maintenance, and support while operations teams can manage the service mesh and operate the app. A service mesh is a specialized infrastructure layer that manages network-based service-to-service communication. This approach allows different sections of an application to interact with one another. Service meshes are frequently used in combination with containers, microservices, and cloud-based applications.
#Cloud Service Mesh Market Size#Cloud Service Mesh Market Share#Cloud Service Mesh Market Growth#Cloud Service Mesh Market Trend#Cloud Service Mesh Market segment#Cloud Service Mesh Market Opportunity#Cloud Service Mesh Market Analysis 2022
0 notes
Text
What is a Service Mesh, and why do you need one?

Imagine a situation where you have to test a new version of your application in a microservices architecture, using canary deployment, or where you have to secure traffic between two services or have to set up a failover strategy in case one of the services is unresponsive. In these circumstances, the traditional network layer of most container orchestration engines is woefully unequipped. Wherever the network layer of these engines has to be augmented, tools such as Service Meshes come into the picture.
What is a service mesh?
A service mesh is a “dedicated infrastructure layer for facilitating service-to-service communications between services or microservices, using a proxy.”
Related articles
Service Mesh: The best way to Encrypt East-West traffic in Kubernetes
How does a No-Code App Builder help enterprises?
Let us look more closely at this definition to understand it better.
“A service mesh is a dedicated infrastructure layer…” — A service mesh is dedicated, which means that unlike built-in network layers which only support core orchestration functionality with basic features, its main purpose is selective and focused. What is its purpose?
“…for facilitating service-to-service communications between services or microservices”. This is fairly self explanatory. But how does it do this?
“…using a proxy.” A proxy is an entity that handles a specific task on behalf of another. In our case, it refers to the data plane of the service that proxies call to and from the service itself.
Having understood what a service mesh is, let’s delve more deeply into why we need it.
Why do we need it?
From the previous section, we understand that service mesh is an infrastructure layer that primarily caters to the microservice architecture pattern, though it is not restricted to that.
Some of the most common problems faced in microservice networks are:
It’s difficult to manage the vast number of microservices, their versions and so on, in and across environments.
The complicated and large networks provide a larger attack vector for cybersecurity threats.
There is a lack of fine-grained control over inter-service networks.
It’s challenging to manage complicated firewall rules and port mappings.
As more people adopt microservices, the above problems are only compounded. This is where the service mesh steps in, to solve these problems.
Features of a service mesh
Service discovery
Using a container management framework, service discovery maintains a list of instances that are ready to be discovered by other services. This helps create and maintain a topological map of the network in real-time. Enabling segregation of services into categories leads to better organization and management. Other important features related to service discovery include health checks, load balancing and failover implementation. By keeping track of healthy instances and recording the unhealthy ones, we can configure service meshes to re-route requests to healthy instances of the same application.
Zero Trust Security Model
With growing adoption of tools such as Kubernetes, Nomad and others, manual configuration of networks is no longer possible. This complexity is increased especially in Kubernetes and public cloud infrastructure, where IP addresses and DNS names change unpredictably. Service mesh allows for the encryption of communication between services using mTLS and also the verification of identity. The service mesh components use proxies to control communication between local service instances and other services in the network. They also ensure that the TLS connections are verified and encrypted.
Fine-grained network control
Proxies attached to services allow us to control traffic and enforce security, but they also allow us to define policies that allow more control over which service is allowed to communicate to whom. This can be done through a simple allow/deny policy. This simplifies the problem mentioned above, regarding complex firewall rules and IP address management.
When you’re working with microservices architecture and technologies like Kubernetes, it’s important to use all the tools at your disposal to simplify the process. Cloud now technologies offer both Application development and Application modernization services. A service mesh is an important part of this process.
#applicationdevelopment#application modernization#app development#app developing company#apps#cloud application development#application#application development and modernization#application modernization services#application development#application development company in USA#web application development
0 notes
Text
Tips to Hire Expert ASP.Net Developers

ASP.NET is an open-source server-side web application framework designed for web development that produces dynamic websites. Developed and introduced in 2002 by Microsoft, ASP.NET helps developers build expert websites, web apps, and web-based services. Hire dot net developer.ASP.NET enhances the .NET developer platform by providing tools and libraries designed specifically for building web-based applications. .NET is an application platform for developers made up of programming languages, tools, and libraries that can be used to create various kinds of applications. Hire Asp.Net Developer
Services of ASP.NET
Fast and Scalable
Hire .net developer. ASP.NET offers the highest performance and speed compared to other web frameworks.
Make Secure Apps
They are offering industry-standard authentication protocols. ASP.NET built-in features provide vital protection for applications against Cross-site scripting (XSS) and cross-site request forgery (CSRF). ASP.NET supports multi-factor authentication as well as external authentication via Google, Twitter, and many more.
Active Community and Open Source
Get fast answers to your questions by joining an engaged community of programmers in Stack Overflow, ASP.NET forums, and many others.
Cross-Platform
Code can run natively on any operating system that supports it, including C#, F#, or Visual Basic. A variety of .NET implementations do the bulk of the work. The .NET framework offers a robust guide for desktop applications and more for Windows.
Libraries
Microsoft and others keep an active package ecosystem based around the .NET Standard to improve and increase capabilities.
Evolved Framework
There are millions of applications that have been developed with .NET in various fields. Build native applications for Windows, iOS, and Android using existing C# skills. You could even employ an expert C# programmer to meet your requirements.
Writing in a language that is continuously evolving and stable is essential. It makes life easier and more enjoyable, but it can also boost employees' productivity and, in certain instances, helps avoid expelled errors and bugs.
Model Binding
Do you know that due to model binding, Razor controllers and pages can work using data derived directly from requests made via HTTP? Concerning this, you will be able to instantly and effortlessly obtain valuable information, with no need to code once more.
This model binding technique extracts information from various sources, such as routes, fields, or inquiry strings. Also, this program provides details to razor pages and controllers within the public domain, as well as parameters and properties.
Asynchronous programming patterns
When you use ASP.NET, you can enjoy excellent help with Asynchronous programming patterns. Async is present across every class in the .NET Framework and most of the libraries.
One of the primary reasons why ASP.NET Core is quicker is the extensive use of synchronous patterns within the developed MVC Frameworks.
Simple to keep
You don't need to think of a lot to grasp this part. The reason for this is easy and sensible. The logic is that it's simple to maintain a smaller amount of code than complicated ones.
It might not be easy for those who have just started as a developer to master this technique. However, for an experienced developer, he knows how to optimize all code within ASP.NET The Core.
It is essential to stay up-to-date with all the most current improvements for language development. Continuously research and study the latest changes to the programming language.
Optimize Data Access
Have you ever thought about the fact that accessing data is among the slowest tasks in any program? It is exhausting and dropping for many developers at times.
One must connect all data access to APIs asynchronously. It is necessary to cut down on roundtrips to the database and retrieve only the needed data. Try not to use projection queries in a collection. In a place where you're using Entity Framework Core to connect to data, be sure that you adhere to the rules and guidelines within Entity Framework Core.
However, on the other side, if you're using a program that does not allow data to be changed by the program, It is suggested that you use the non-tracking query.
Characteristics of ASP.Net
Cross-platform support
With the development of technology today, developers can benefit from cross-platform features through ASP.Net and use the solution for Windows, Linus, and Mac OS.
More reliable performance
Performance is the first aspect when developing projects with the most recent update to the ASP. Net framework. Developers are now able to enjoy improved performance and speed when creating web-based applications. An ASP.Net specialist will notice the changes in the performance of applications developed using ASP. Net technology in comparison to other options. Other features such as networking and concurrency, compression, and serialization can compute with more incredible speed in the latest version.
Additionally, it reduces it is also smaller in size. HTTP request size has been decreased to 2Kb, which further improves the performance.
Applications hosted by self-hosted
ASP.net developers can now build self-hosted applications with the technology without relying on the Internet Information Service(IIS). The applications are hosted by themselves. When it is about Linux systems, web applications are hosted with Nginx. IIS and Nginx provide opposite proxy support for these types of applications.
Support of SignalR Java Client
SignalR Java client is comprised of components of Javascript on both the client as well as server sides. Designed especially for .Net Framework, The SignalR Java Client library permits the server to send out asynchronous notifications to applications installed on the client-side. Developers can utilize this client to include features in the application in real-time. Besides this, the client chooses the most appropriate method of transportation depending on the available resources on both the server and the client-side.
The razor page's introduction
A new feature in ASP.Net includes the creation of razor pages. The pages simplify the coding process and increase efficiency. With these pages, developers cannot develop self-sufficient views for controllers that allow them to create scenarios that are related to development. The ease of making these scenarios lets developers get a good overview of the entire architecture of the software.
Development Models
Web
Develop web-based applications and services on various platforms, including Windows, Linux, macOS, and Docker.
Mobile
A single codebase enables you to create native mobile applications on iOS, Android, and Windows.
Desktop
Create stunning and persuasive desktop applications designed for Windows or macOS.
Microservices
Microservices that can be individually used and are run by Docker container.
Gaming
Design engaging and well-known 2D and 3D-based games agreeable with the most popular PCs, smartphones, consoles, and desktops.
Machine Learning
Use different vision algorithms, prediction models, speech processors, and much more to your applications.
Cloud
Consume cloud services that are already available or design and launch an app of your own.
Internet of Things
Create IoT applications that have an integrated support system as well as other single-board computers.
Here are Tips to Hire Remote ASP.NET Developers
Professional technical screening of .NET developer abilities in a video or phone interview.
It is essential to screen ASP.NET developers to draw what skills they possess. To employ committed remote ASP.Net developers, you must know the candidate's background and technical knowledge by asking them direct questions about the skills you're looking to confirm. You can ask questions regarding ASP.NET MVC and know developers' capabilities to build reliable and secure web-based apps. The questions you ask must be different based on the job you're looking to fill and the skills you are looking to approve.
Online Coding Test
Online coding tests can be an excellent method of explaining the experience of ASP.NET developers. Performing online coding tests could assist in evaluating applicants more effectively than interview screening or resume screening.
Based on your business's strategy, coding tests can are an excellent method for screening .NET developer abilities or an additional option, in addition to an analysis of the resume and a phone meeting. Keep examining to find programming tests that will simplify your screening process for technical skills and what should be included to give precise details.
Many companies are turning to coding tests as the primary screening method, as they offer IT recruiters two significant advantages:
Tests on the internet should prove not just .NET developer abilities but also the knowledge of buildings and frameworks.
.NET Coding tests must include programming tasks that are to the roles that candidates are expected to fulfill when they are hired.
They are thinking about creating .NET programming tasks that are based on the code of the company. This is one of the best methods to imitate the job candidates' problems when they are hired.
A programming task that will review challenges in coding.
.NET Developer skills provide information on the applicant's background, his approach to code quality, and how effectively they debug and identify the traps.
Coding tests demonstrate an interest in the selection process, which has an impact that is positive on the candidate's involvement.
Measure the Experience Level
Experience working on massive projects that require a large amount of information. This suggests that the candidate may be able to tackle problems that may arise during every IT project.
Developers are invited to gatherings and programming events is an indication that the applicant is aware of the latest trends and best practices. It is possible to be a skilled and passionate developer.
Suppose a developer is involved in Open-source projects or is a member in meetings. The candidate is informed of .NET technology and is likely to be a part of the project.
0 notes
Text
Overview of Design Patterns for Microservices

What is Microservice?
Microservice architecture has become the de facto choice for modern application development. I like the definition given by “Martin Fowler”.
In short, the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies. — Martin Fowler
Principles of microservice architecture:
Scalability
Availability
Resiliency
Independent, autonomous
Decentralized governance
Failure isolation
Auto-Provisioning
Continuous delivery through DevOps
What are design patterns?
Design patterns are commonly defined as time-tested solutions to recurring design problems. Design patterns are not limited to the software. Design patterns have their roots in the work of Christopher Alexander, a civil engineer who wrote about his experience in solving design issues as they related to buildings and towns. It occurred to Alexander that certain design constructs, when used time and time again, lead to the desired effect.
Why we need design patterns?
Design patterns have two major benefits. First, they provide you with a way to solve issues related to software development using a proven solution. Second, design patterns make communication between designers more efficient. Software professionals can immediately picture the high-level design in their heads when they refer the name of the pattern used to solve a particular issue when discussing system design.
Microservices is not just an architecture style, but also an organizational structure.
Do you know the “Conway’s Law”?
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure. — Melvin Conway, 1968
Microservices Design patterns:
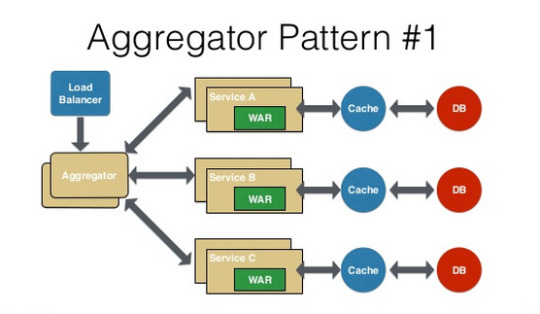
Aggregator Pattern — It talks about how we can aggregate the data from different services and then send the final response to the consumer/frontend.
Proxy Pattern — Proxy just transparently transfers all the requests. It does not aggregate the data that is collected and sent to the client, which is the biggest difference between the proxy and the aggregator. The proxy pattern lets the aggregation of these data done by the frontend.

Chained Pattern — The chain design pattern is very common, where one service is making call to other service and so on. All these services are synchronous calls.

Branch Pattern — A microservice may need to get the data from multiple sources including other microservices. Branch microservice pattern is a mix of Aggregator & Chain design patterns and allows simultaneous request/response processing from two or more microservices.

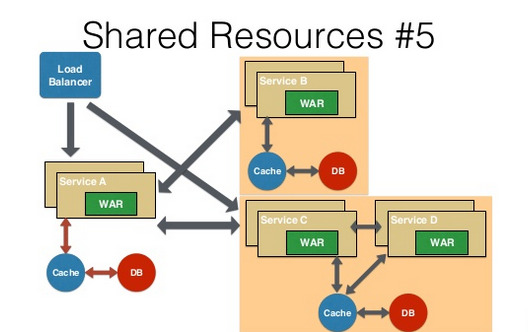
Shared Resources Pattern — One database per service being ideal for microservices. This is anti-pattern for microservices. But if the application is a monolith and trying to break into microservices, denormalization is not that easy. A shared database per service is not ideal, but that is the working solution for the above scenario.
Asynchronous Messaging Pattern — In an message based communication , the calling service or application publish a message instead of making a call directly to another API or a service. An message consuming application(s) then picks up this message and then carries out the task. This is asynchronous because the calling application or service is not aware of the consumer and the consumer isn’t aware of the called application as well.

There are many other patterns used with microservice architecture, like Sidecar, Event Sourcing Pattern, Continuous Delivery Patterns, and more. The list keeps growing as we get more experience with microservices.

Let me know what microservice patterns you are using.
Thank you for reading :)
Source:
#Design Patterns for Microservices#microservices#Mobile App Design#web design services#UI UX Design#WeCode Inc#Japan
0 notes
Text
Impress Websites: DevOps/Developer - Europe only

Headquarters: Västerås, Sweden URL: http://impress.website
Impress is a website-as-a-service provider purpose-built for resellers. We host and fully manage websites for companies that sell website solutions, but do not want to technically manage their clients' websites.
Now, we are looking to expand our team with remote positions, starting with IT operations. Remote is not new to us as a company, we have always had offices in Serbia and Sweden. We also have several team members working completely or partly remote.
We offer a fast-paced and fun workplace with a friendly and open atmosphere. Our whole team meets in different European locations twice a year for a team-building/company meetup.
We are looking for someone that can work independently and with great communication skills. We expect our team members to be able to work in a self-driven mode while understanding and keeping track of their responsibilities.
Responsibilities:
Design, estimate, and code new features
Participate in software design discussions
Ability to work in a collaborative team environment
Coordination with team leads/managers and tester(s) during development
Skills:
Excellent verbal and written communication skills in English
Good knowledge of design and architectural patterns and development best practices
Familiar with Service-oriented architecture (SOA) / Microservices design patterns
Familiar with message brokers and event-based communication (RabbitMQ)
Designing Restful API
Extensive knowledge and experience of .netcore WebAPI framework
MySQL database schema design
Familiar with Linux
Huge plus if you know:
Understand and design system architecture
Solid networking knowledge: firewall, proxy, routing, ...
Solid Linux administration/operation knowledge: CentOS/AmazonLinux, Debian, Ubuntu...
Containers & Orchestration: Docker, Kubernetes
Amazon Web Services: RDS, S3, EFS, CloudFront, EKS, ECR, Route53...
Infrastructure as Code principles and tools: Ansible, Cloudformation, ...
Scripting: Bash, python...
What we offer:
Work where you’re most productive
Flexible working hours so you are free to plan the day
Whatever equipment you need to do great work
Gym or other sports/fitness contribution
Health and pension insurance
If you like working from a Coworking space, you can do it and we will pay (and yes it is allowed to just buy lattes so the cafe doesn’t kick you out)
Keep growing by attending a local paid conference a year
2 x annual teams retreats
If you feel that you are the person we are looking for and that you are up for a challenge, we are anxious to meet with you. Please send your CV on [email protected] and make sure to write a personal note specifically for this application. We value written English and we would love to hear why you are a great fit for us.
To apply: [email protected]
from We Work Remotely: Remote jobs in design, programming, marketing and more https://ift.tt/3bqemnh from Work From Home YouTuber Job Board Blog https://ift.tt/2vnYe5m
0 notes
Text
Best Tools to Manage Microservices

Microservices can be seen as a process of developing software systems that emphasize on structuring solo function modules with precise actions and interfaces. Being one of the pillars of IoT, they are growing to become the standard architecture. The microservice architecture ensures continuous placement/transport of intricate applications, allowing establishments to advance their tech infrastructure.
As more organizations migrate from monoliths to microservices, they encounter new challenges connected with the way distributed systems are organized. Having hundreds of microservices, you end up with a spider web of connections and concerns about organizing these connections effectively.
There are a number of tools helping engineers to design the microservices architecture and deploy it, Kubernetes (K8s) being probably one of the most popular of them.
However, even when you manage the installation of all components, there remain questions of maintenance, eventual upgrades or changing them. Management is a burden that requires request routing, service observability, rate limiting (incoming and outgoing), authentication, failure management and fault injection, circuit breakers, rolling upgrades, and telemetry.
Service mesh
To manage deployed services, special communicators are used that are called service meshes. A service mesh is a configurable, low-latency infrastructure layer. It is designed to handle a high volume of network-based interprocess communication among application infrastructure services using APIs. A service mesh ensures that such communication is fast, reliable, and secure by providing critical capabilities such as service discovery, load balancing, encryption, observability, traceability, authentication and authorization, and support for the circuit breaker pattern.
A service mesh is a networking model that is somewhat analogous to TCP/IP but at a higher layer of abstraction. Like TCP, the service mesh abstracts the mechanics of delivering requests between services and it doesn’t care about the actual payload or how it’s encoded. Its goal is to provide a uniform, application-wide point for introducing visibility and control into the application runtime.
In practice, the service mesh is usually implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware.
As a service mesh grows in size and complexity, it can become harder to understand and manage. Different companies try to come up with service mesh solutions that would ensure effective management of microservices. The best solutions, in our opinion, are
Istio,
Linkerd (merged with Conduit), and
Consul (Connect).
Istio
Istio is an open source service mesh launched in 2017 by Google, IBM, and Lyft that is designed to connect, secure, and monitor microservices. It has two planes, a control plane and data plane. The data plane is composed of a set of intelligent Envoy proxies, deployed as sidecars, which prevents communication between microservices from altering the application code. Envoy proxies provide dynamic service discovery, load balancing, TLS termination, HTTP/2 and gRPC proxies, circuit breakers, health checks, staged rollouts with %-based traffic split, fault injection, and rich metrics. The control plane manages and configures the proxies to route traffic. It comprises three components:
Pilot, the core component used for traffic management that configures all Envoy proxy instances;
Mixer, a platform-independent component that enforces access control and usage policies across the service mesh and collects and analyzes telemetry reports; and
Citadel, the Certificate Authority and Policy enforcer.
Istio layers transparently onto existing distributed applications. Moreover, it is also a platform, including APIs that let it integrate into any logging platform, or telemetry or policy system.

Istio benefits:
rich features, including automatic load balancing for HTTP, gRPC, WebSocket, and TCP traffic;
fine-grained control of traffic behaviour with extensive routing rules, retries, failovers, and fault injection;
pluggable policy layer and configuration API that supports access controls, rate limits, and quotas;
automatic metrics, logs, and traces of all traffic within a cluster;
strong identity-based authentication and authorization policies;
secure service-to-service communication.
Linkerd
Linkerd is a fully open-source service mesh for Kubernetes and other frameworks developed as a Cloud Native Computing Foundation project in the Linkerd GitHub organization. In 2018 it merged with Conduit to form Linkerd 2.0, growing from a cluster-wide service mesh to a composable service sidecar. It can do end-to-end encryption and automatic proxy injection but lacks complex routing and tracing capabilities.
Architecturally, Linkerd has the control plane and the data plane. The control plane is a set of services that run in a dedicated namespace. Within the control plane, the Controller consists of multiple containers (including public-api, proxy-api, destination, tap) that provide most functionalities: aggregate telemetry data, provide a user-facing API, provide control data to the data plane proxies, etc. Linkerd uses Prometheus, to expose and store metrics, whilst the Grafana dashboard renders and displays dashboards that can be reached from the Linkerd dashboard. The data plane consists of ultralight transparent proxies running next to each service instance. Because they’re transparent, these proxies act as out-of-process network stacks, sending telemetry to, and receiving control signals from the control plane. With this design, Linkerd measures and manipulates traffic to and from your service without introducing excessive latency.

Linkerd benefits:
a lightweight service mesh that can be placed on top of any existing platform;
simple installation and CLI tools and doesn’t require a platform admin to be used;
easy services running with runtime debugging, observability, reliability, and security
Linkerd doesn’t offer a rich array of features, but it is an easy service mesh that can be ideal for organizations that aren’t operating vast amounts of microservices.
Consul Connect
Consul Connect, launched by HashiCorp in July, 2018, is an extension of Consul, a highly available and distributed service discovery and KV store. It adds service mesh capabilities and provides secure service-to-service communication with automatic TLS encryption and identity-based authorization. It emphasises service discovery and service identity management. Similarly to Istio and Linkerd, it uses the Envoy proxy and the sidecar pattern.
As an extension of Consul, Consul Connect synchronizes Kubernetes and Consul services. It also offers integrations with Vault for certificate and secret management, further extending the service discovery provided by Consul.
Consul Connect uses mutual TLS to automatically encrypt communications between containers. The cluster consists of multiple EC2 instances, each running a Consul agent which is connected to a central Consul server which tracks what tasks are running in the cluster, and their location.
Each such task is made up of an application container, and a Consul Connect sidecar container. On startup, the Consul Connect sidecar registers the application container’s IP address into Consul via the Consul agent. The Consul Connect sidecar can also be configured to provide a local proxy that serves as a secure network channel to another application container.
The data plane for Consul and, by extension, for Consul Connect, is pluggable. It includes a built-in proxy with a larger performance trade off for ease of use and optionally third party proxies such as Envoy. The ability to use the right proxy for the job allows flexible heterogeneous deployments where different proxies may be more correct for the applications they’re proxying.
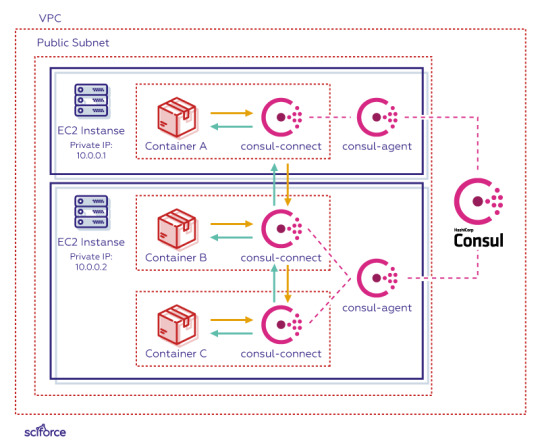
Consul Connect benefits:
unique capabilities when implementing multi-cluster workloads or when working with a heterogeneous infrastructure;
connections via gateways to enable connections between services in each datacenter without externally routable IPs at the service level;
intention replications;
security policy implementation between different clusters to ensure the persistence of the security model.
As you can see, Istio, Linkerd, and Consul Connect have their benefits that may or may not match your technology stack’s requirements.
In brief, Istio is the most advanced service mesh available, but it is at the same time more complex and difficult to manage.
Linkerd is easier but less flexible, so it is mostly suitable for smaller projects that require satisfactory performance with less effort.
Consul Connect offers integrations with other HashiCorp solutions, Consul and Vault.
At present, the task remains tough with many organizations starting the journey but encountering multiple issues on the way. Many settle with a mix of monolith and microservices as a workaround, but future growth of microservices as part of the IoT ecosystems is likely to push them to full transfer — requiring new friendlier tools for deployment and management. Therefore, we’ll soon see more solutions that would be able to address specific problems or will offer easier ways to manage microservices.
0 notes
Text
Google Analytics (GA) like Backend System Architecture
There are numerous way of designing a backend. We will take Microservices route because the web scalability is required for Google Analytics (GA) like backend. Micro services enable us to elastically scale horizontally in response to incoming network traffic into the system. And a distributed stream processing pipeline scales in proportion to the load.
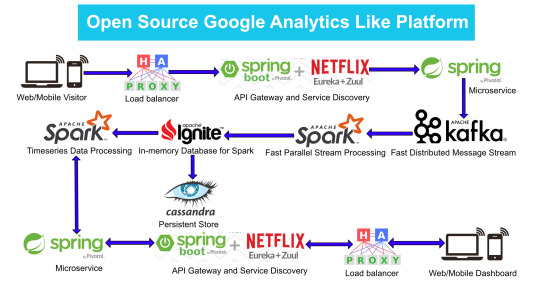
Here is the High Level architecture of the Google Analytics (GA) like Backend System.
Components Breakdown
Web/Mobile Visitor Tracking Code
Every web page or mobile site tracked by GA embed tracking code that collects data about the visitor. It loads an async script that assigns a tracking cookie to the user if it is not set. It also sends an XHR request for every user interaction.
HAProxy Load Balancer
HAProxy, which stands for High Availability Proxy, is a popular open source software TCP/HTTP Load Balancer and proxying solution. Its most common use is to improve the performance and reliability of a server environment by distributing the workload across multiple servers. It is used in many high-profile environments, including: GitHub, Imgur, Instagram, and Twitter.
A backend can contain one or many servers in it — generally speaking, adding more servers to your backend will increase your potential load capacity by spreading the load over multiple servers. Increased reliability is also achieved through this manner, in case some of your backend servers become unavailable.
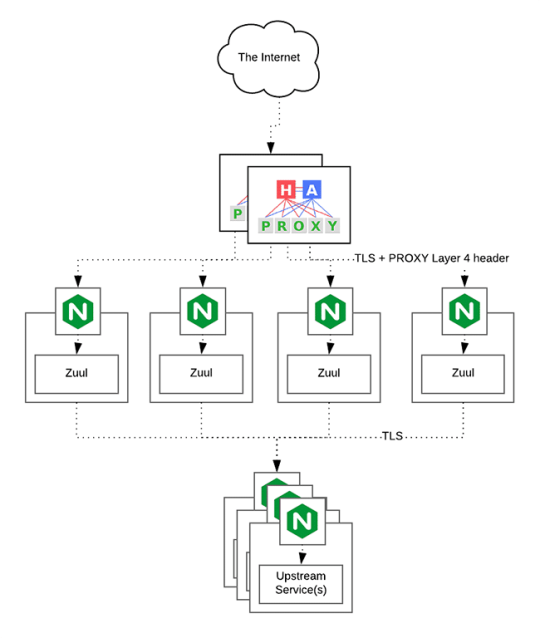
HAProxy routes the requests coming from Web/Mobile Visitor site to the Zuul API Gateway of the solution. Given the nature of a distributed system built for scalability and stateless request and response handling we can distribute the Zuul API gateways spread across geographies. HAProxy performs load balancing (layer 4 + proxy) across our Zuul nodes. High-Availability (HA ) is provided via Keepalived.
Spring Boot & Netflix OSS Eureka + Zuul
Zuul is an API gateway and edge service that proxies requests to multiple backing services. It provides a unified “front door” to the application ecosystem, which allows any browser, mobile app or other user interface to consume services from multiple hosts. Zuul is integrated with other Netflix stack components like Hystrix for fault tolerance and Eureka for service discovery or use it to manage routing rules, filters and load balancing across your system. Most importantly all of those components are well adapted by Spring framework through Spring Boot/Cloud approach.
An API gateway is a layer 7 (HTTP) router that acts as a reverse proxy for upstream services that reside inside your platform. API gateways are typically configured to route traffic based on URI paths and have become especially popular in the microservices world because exposing potentially hundreds of services to the Internet is both a security nightmare and operationally difficult. With an API gateway, one simply exposes and scales a single collection of services (the API gateway) and updates the API gateway’s configuration whenever a new upstream should be exposed externally. In our case Zuul is able to auto discover services registered in Eureka server.
Eureka server acts as a registry and allows all clients to register themselves and used for Service Discovery to be able to find IP address and port of other services if they want to talk to. Eureka server is a client as well. This property is used to setup Eureka in highly available way. We can have Eureka deployed in a highly available way if we can have more instances used in the same pattern.
Spring Boot Microservices
Using a microservices approach to application development can improve resilience and expedite the time to market, but breaking apps into fine-grained services offers complications. With fine-grained services and lightweight protocols, microservices offers increased modularity, making applications easier to develop, test, deploy, and, more importantly, change and maintain. With microservices, the code is broken into independent services that run as separate processes.
Scalability is the key aspect of microservices. Because each service is a separate component, we can scale up a single function or service without having to scale the entire application. Business-critical services can be deployed on multiple servers for increased availability and performance without impacting the performance of other services. Designing for failure is essential. We should be prepared to handle multiple failure issues, such as system downtime, slow service and unexpected responses. Here, load balancing is important. When a failure arises, the troubled service should still run in a degraded functionality without crashing the entire system. Hystrix Circuit-breaker will come into rescue in such failure scenarios.
The microservices are designed for scalability, resilience, fault-tolerance and high availability and importantly it can be achieved through deploying the services in a Docker Swarm or Kubernetes cluster. Distributed and geographically spread Zuul API gateways route requests from web and mobile visitors to the microservices registered in the load balanced Eureka server.
The core processing logic of the backend system is designed for scalability, high availability, resilience and fault-tolerance using distributed Streaming Processing, the microservices will ingest data to Kafka Streams data pipeline.
Apache Kafka Streams
Apache Kafka is used for building real-time streaming data pipelines that reliably get data between many independent systems or applications.
It allows:
Publishing and subscribing to streams of records
Storing streams of records in a fault-tolerant, durable way
It provides a unified, high-throughput, low-latency, horizontally scalable platform that is used in production in thousands of companies.
Kafka Streams being scalable, highly available and fault-tolerant, and providing the streams functionality (transformations / stateful transformations) are what we need — not to mention Kafka being a reliable and mature messaging system.
Kafka is run as a cluster on one or more servers that can span multiple datacenters spread across geographies. Those servers are usually called brokers.
Kafka uses Zookeeper to store metadata about brokers, topics and partitions.
Kafka Streams is a pretty fast, lightweight stream processing solution that works best if all of the data ingestion is coming through Apache Kafka. The ingested data is read directly from Kafka by Apache Spark for stream processing and creates Timeseries Ignite RDD (Resilient Distributed Datasets).
Apache Spark
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
It provides a high-level abstraction called a discretized stream, or DStream, which represents a continuous stream of data.
DStreams can be created either from input data streams from sources such as Kafka, Flume, and Kinesis, or by applying high-level operations on other DStreams. Internally, a DStream is represented as a sequence of RDDs (Resilient Distributed Datasets).
Apache Spark is a perfect choice in our case. This is because Spark achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine.
In our scenario Spark streaming process Kafka data streams; create and share Ignite RDDs across Apache Ignite which is a distributed memory-centric database and caching platform.
Apache Ignite
Apache Ignite is a distributed memory-centric database and caching platform that is used by Apache Spark users to:
Achieve true in-memory performance at scale and avoid data movement from a data source to Spark workers and applications.
More easily share state and data among Spark jobs.
Apache Ignite is designed for transactional, analytical, and streaming workloads, delivering in-memory performance at scale. Apache Ignite provides an implementation of the Spark RDD which allows any data and state to be shared in memory as RDDs across Spark jobs. The Ignite RDD provides a shared, mutable view of the same data in-memory in Ignite across different Spark jobs, workers, or applications.
The way an Ignite RDD is implemented is as a view over a distributed Ignite table (aka. cache). It can be deployed with an Ignite node either within the Spark job executing process, on a Spark worker, or in a separate Ignite cluster. It means that depending on the chosen deployment mode the shared state may either exist only during the lifespan of a Spark application (embedded mode), or it may out-survive the Spark application (standalone mode).
With Ignite, Spark users can configure primary and secondary indexes that can bring up to 1000x performance gains.
Apache Cassandra
We will use Apache Cassandra as storage for persistence writes from Ignite.
Apache Cassandra is a highly scalable and available distributed database that facilitates and allows storing and managing high velocity structured data across multiple commodity servers without a single point of failure.
The Apache Cassandra is an extremely powerful open source distributed database system that works extremely well to handle huge volumes of records spread across multiple commodity servers. It can be easily scaled to meet sudden increase in demand, by deploying multi-node Cassandra clusters, meets high availability requirements, and there is no single point of failure.
Apache Cassandra has best write and read performance.
Characteristics of Cassandra:
It is a column-oriented database
Highly consistent, fault-tolerant, and scalable
The data model is based on Google Bigtable
The distributed design is based on Amazon Dynamo
Right off the top Cassandra does not use B-Trees to store data. Instead it uses Log Structured Merge Trees (LSM-Trees) to store its data. This data structure is very good for high write volumes, turning updates and deletes into new writes.
In our scenario we will configure Ignite to work in write-behind mode: normally, a cache write involves putting data in memory, and writing the same into the persistence source, so there will be 1-to-1 mapping between cache writes and persistence writes. With the write-behind mode, Ignite instead will batch the writes and execute them regularly at the specified frequency. This is aimed at limiting the amount of communication overhead between Ignite and the persistent store, and really makes a lot of sense if the data being written rapidly changes.
Analytics Dashboard
Since we are talking about scalability, high availability, resilience and fault-tolerance, our analytics dashboard backend should be designed in a pretty similar way we have designed the web/mobile visitor backend solution using HAProxy Load Balancer, Zuul API Gateway, Eureka Service Discovery and Spring Boot Microservices.
The requests will be routed from Analytics dashboard through microservices. Apache Spark will do processing of time series data shared in Apache Ignite as Ignite RDDs and the results will be sent across to the dashboard for visualization through microservices
0 notes
Text
Leveraging microservices for your business, Part 2: The good and the bad
In this article, senior architect Matt Bishop reviews the benefits and difficulties with a microservice architecture. While avoiding the “anti-patterns” and horror stories that are prevalent while sticking to the architecture qualities themselves.
Quick recap on considering microservices
In the first installment of the microservices series it laid out the definition of microservices from their qualities – loosely coupled, service-oriented and bounded contexts. These qualities enable a lot of things, but they also suffer some challenges.
The Good
A well-built microservices system delivers fundamental implementation independence. The services in the system are largely independent of each other and free to develop at their own pace. The system release changes often, without much coordination between the components. Over time the system acts more like an ecosystem where the whole business is supported by the coordination and ever-improving capabilities found therein.
An ecosystem like this has some observable characteristics:
Small Teams: Amazon calls these “2-pizza” teams, where the entire team could be fed dinner on two pizzas. This small size reduces the need for process and management as they communicate with each other and share the goals and work internally. The team knows their bounded context and the shared identifiers they must work with. They understand their service’s orientation in the system.
Self-Contained Technology Choices: Developers find this aspect of microservices the most appealing because they have the freedom to make the “right” choice for a service given its requirements. The language, the database, the libraries, and other implementation technologies are owned by the team. They do not have to share these with other components because they are loosely coupled.
Independently Scalable: Each service must manage their own quality-of-service requirements and is free to find the most suitable way to do so. For some services, horizontal scaling is the best answer. For others, it might be caching, especially if they proxy from an external system. Similarly, microservices that coordinate with other services can mitigate problematic QoS with patterns like circuit breaker to keep their own QoS intact. The system can deal with service outages without bringing down the entire business.
Replaceable: Every business system must respond to change, and with a microservices architecture, one response is replacement. Perhaps the bounded context was incorrectly-defined and a service needs to be split into multiple services. It might be that the external service being proxied has been changed and it is faster to replace the service with a new one, rather than versioning the code itself. In some cases, the service codebase cannot be reliably recovered and redeployed due to staff changes or technology failures. A single microservice is small enough that completely replacing it with another is an inexpensive and fast option.
The Bad
Every architectural style has its challenges, and microservices are no different. These challenges are hard to mitigate and may spell doom for the ecosystem.
Governance: While the teams are small and independent, the requirements for each service must be governed effectively. Someone has to decide the shape of the bounded contexts, the shared identifiers and QoS for each service. The overall architecture must fulfil the business mission successfully.
Consumption: The various services are consumed in a variety of ways, from web sites and mobile apps to external systems. How do these consumers discover the relevant services that vend a needed capability? How do they coordinate the services when multiple services are required to complete a user journey? Often a consumer team will have to build their own microservices to accomplish their goals. These patterns, like backend-for-frontend, add more complexity and coupling between components.
Cross-Cutting Concerns: Many aspects of a system go through many, even all, parts of the microservices. A cross-cutting concern is driven by business requirements and must be satisfied by all the relevant microservices. Most concerns are solved with centralized monitoring and logging capabilities that every service must participate in. Performance analysis, state change traceability, user authorization, data security, GDPR, security, licensing and many other concerns flow through the ecosystem and must be reliably addressed by all the microservices.
Cost: A well-designed microservice that scales well, maintains its own data persistence and participates in cross-cutting observability systems may, in itself, be inexpensive. Infrastructure technology like virtualization, containerization, serverless functions and on-demand data storage have made microservices possible yet are often more expensive than realized at the outset. Companies are often surprised by how extensive (and expensive) their AWS and Azure invoices are. A single microservice can cost several hundred dollars per month in service fees just to idle. Multiplying this out to all the microservices in an ecosystem, including the multiple regions required to run a global service, and the bill can be staggering, even ruinous. A business will be sorely tempted to combine the expensive parts like databases to reduce costs. Naturally the now-shared infrastructure violates the microservice independence qualities.
A large-scale microservice ecosystem is truly a challenge for any business to undertake. One must have significant talent and resources to take this path and follow it properly, without shortcuts or deviations. Although this article did not address the anti-patterns, they do exist and they lead to system failure.
Check back for Matt’s last installment of the microservices series where he puts it all together for addressing challenges while reaping the benefits of microservices.
The post Leveraging microservices for your business, Part 2: The good and the bad appeared first on Get Elastic Ecommerce Blog.
Leveraging microservices for your business, Part 2: The good and the bad published first on https://getyourcoupon.tumblr.com/
0 notes
Text
API Life Cycle Basics: Gateway
API gateways have long played a role in providing access to backend resources via web services and APIs. This is how web services have historically been deployed, but it is also how modern web APIs are being managed. Providing a gateway that you can stand up in front of existing web APIs, and proxy them through a single gateway that authenticates, logs, and manages the traffic that comes in and out. There are many management characteristics of API gateways, but I want to provide a stop along the API lifecycle that allows us to think about the API deployment, as well as the API management aspects of delivering APIs. I wanted to separate out the API gateway discussion from deploy and manage, focusing specifically on the opportunities to deploy one or many gateways, while also looking at it separately as a pattern in service of microservices. While code generation for API deployment is common, gateways are making a resurgence across the sector when it comes to working with a variety of backend systems, on-premise and in the cloud. There are many API gateway solutions available on the market, but I wanted to focus in on a handful that help span deployment and management, as well as allowing for new types of routing, and transformation patterns to emerge. Here are a couple of the gateway solutions I’m studying more these days: https://goo.gl/1yGVb4 #DataIntegration #ML
0 notes